Ensuring Data Trustworthiness
Data Analytics ETL
Veracity means accurate and trustworthy of data. This post is part of a series about the Fundamentals of Data Analytics, you can find out more related topics from the main post here Understanding the 5 Vs of Big Data
Veracity deals with the trustworthiness of the data and integrity is a key factor that affects the data trustworthiness. This is usually done in different phases of the data lifecycle. The lifecycle of data includes; creating, aggregation, storage, access, sharing, archiving and disposing. Let’s see what they mean anyway..
Data lifecycle
Creation: Is the phase when data integrity means ensuring data is accurate, it generally involves software-based audit.
Aggregation: During the aggregation phase, mistakes in creating totals are usually small. However, issues can happen if people misinterpret what the totals mean. For example, comparing total sales for a quarter with just the sales of shipped orders can lead to confusion.
Storage: When data is stored and not being used, it can be changed or tampered with. That’s why regular checks are important to ensure the data stays accurate.
Access: During the access phase, users obtain their permissions to view analytical data. Systems should be configured as read-only and subjected to regular audits to identify any unusual access behaviors.
Sharing: The sharing phase is crucial for assessing the reliability of your system. Users typically have clear expectations regarding the reports they generate. When the figures presented do not align with their anticipations, doubts about the accuracy of the data may arise.
Archiving: For the archiving phase, data eventually reaches a stage where it no longer holds immediate significance. At that juncture, it should be archived. Ensuring that data security is paramount; access to these repositories should be really tightly controlled and set to read-only because it will not be changing.
Disposal: The disposal phase is particularly significant in certain regulatory contexts. Retaining data that no longer serves a purpose can expose the organization to unwarranted risks. Therefore, it is essential to destroy data at some point to ensure safety and comply with regulations, such as the General Data Protection Regulation (GDPR) in the European Union.
Besides managing data, there are other concerns about data quality inside and outside the organization. Internally, companies can suggest fixes if they spot problems with data quality. For external data sources, it’s important to check the quality and make changes if there are accuracy issues.
When gathering data for analysis, there’s a risk of data getting corrupted. This could mean missing information, broken rules, or incorrect values being entered.
To fix these problems, data cleaning needs to happen during the data gathering phase. This process finds and corrects corrupted data in records, tables, databases, or files. It’s an essential part of the extract, transform, and load (ETL) process. Each time data is pulled from its source, it gets checked and cleaned.
After cleaning the data, companies must maintain its quality by using database schemas. A database schema is a structure that organizes data and ensures it follows certain rules, such as how different data items relate to each other.
Data integrity and preventing potential issues
Data changes with time. When it moves between processes or systems, it can lose its accuracy. Here’s a table that looks at data integrity.
| Importance of Data Integrity | Identifying Data Integrity Issues |
|---|---|
| You need to be confident that the data you’re analyzing is reliable. The truthfulness of the data depends on its integrity. Ensuring data integrity means making sure your data is trustworthy. It’s important to verify its integrity and ensure that the entire data chain remains secure and uncompressed. By understanding the complete lifecycle of your data and knowing how to protect it properly, you can significantly enhance its integrity. | A data analyst may need to conduct data integrity checks, looking for possible issues. Data can come from internal and external sources. While they can’t change external data, they can suggest improvements for internal sources they work with. Analysts must assess the integrity of these data sources and make adjustments if there are any problems. |
Transforming data with the ETL process
ETL (Extract, Transform, Load) is the process of gathering data from raw sources, changing it into a standard format, and then loading it into a final location for analysis. It uses business rules to process data from various sources before integrating it centrally.
The purpose of the ETL process
The ETL process has the following purposes:
- To ensure data accuracy, precision, and depth.
- To create specific data sets for key business questions.
- To combine data from various sources for a complete view.
Extract Data (click to expand!)
The extraction phase is the most crucial part of the process. Data for analytics often comes from various sources and types, like transaction logs, product databases, public data, or application streams.
You need to plan for four key areas:
- Identify where all source data is located, which may be on-premises or online.
- Plan when to extract the data, considering the impact on the source system.
- Decide where to store the data during processing, known as the staging location.
- Determine how often the extraction should occur.
Once you know your data sources and needs, you will extract the information and place it in the staging location.
Transform Data (click to expand!)
Transforming data into a uniform, queryable format is the core of the ETL process. This phase uses rules and algorithms to shape the data into its final form, including data cleansing.
Transformations can be simple, like updating formats or replacing values, such as changing NULL values to zero or replacing "female" with "F." These small changes can significantly enhance the data's usefulness for analysts during visualization.
Transformations can also be more complex, involving business rules to calculate new values. Common transformations include filtering, joining data, aggregating rows, splitting columns, and validating data.
Load Data (click to expand!)
The final phase of the ETL process involves storing the newly transformed data. The planning done during the extraction phase will determine the format of the final data store, which could be a database, data warehouse, or data lake. Once the process is complete, the data in this location is ready for analysis.
ELT process steps
In modern cloud environments, the ELT (Extract, Load, Transform) approach loads data in its original form first and then transforms it later based on use cases and analytics needs.
The steps are similar to ETL but in a different order, leading to similar outcomes.
The ELT process requires more upfront planning. Analytics must be involved early to define data types, structures, and relationships.
The three steps of ELT are:
- Extract raw data from various sources.
- Load it into a data warehouse or data lake in its natural state.
- Transform it as needed within the target system.
With ELT, data cleansing, transformation, and enrichment happen inside the data warehouse, allowing for multiple interactions and transformations of the raw data.
A comparison of the ETL and ELT processes
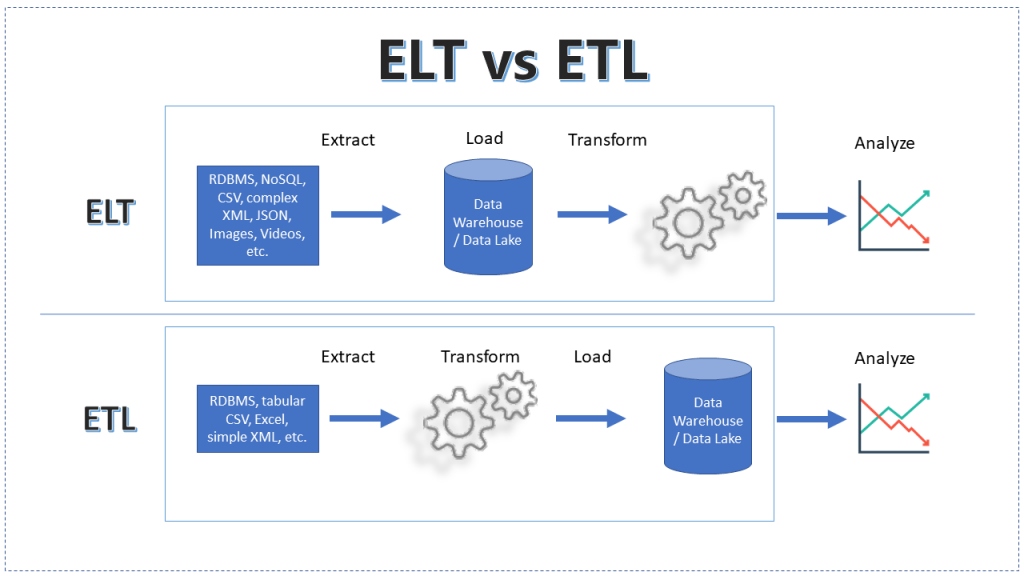
In 2024 and beyound data scientists primarily use ETL to load legacy databases into data warehouses and use ELT with modern databases.
Conclusion
Understanding data veracity is essential for ensuring the trustworthiness and reliability of your data, which is fundamental in any data analytics process. As we’ve explored, maintaining data integrity across its lifecycle—from creation and aggregation to storage, access, sharing, archiving, and disposal—requires careful planning and robust systems.
By focusing on data quality and integrity, you can avoid potential pitfalls that may compromise your data’s accuracy. Implementing thorough data cleaning processes and establishing strong database schemas are critical steps in preserving data veracity. Additionally, the ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes play a vital role in preparing data for analysis by ensuring it is accurate, consistent, and usable.
In the evolving landscape of big data, data scientists and analysts must be vigilant about data veracity to derive meaningful insights and make informed decisions. By prioritizing data integrity and employing best practices in data management, organizations can enhance the value of their data and build a solid foundation for successful data analytics.
For more insights on the fundamentals of data analytics, check out the main post in this series: Understanding the 5 Vs of Big Data.